OpenAI is fortifying its internal safety protocols to counteract potential threats posed by harmful AI. A newly formed “safety advisory group” will hold authority above the technical teams, advising leadership, while the board has been vested with veto power — whether they will exercise this authority remains uncertain.
Normally, the intricacies of such policies might not draw much attention, often leading to closed-door meetings with obscure functions and responsibility structures that remain mostly concealed to outsiders. However, given the recent internal upheavals and ongoing discussions regarding AI risks, it’s worthwhile examining how the foremost AI development company is addressing safety concerns.
In a fresh document and blog post, OpenAI delves into its revised “Preparedness Framework,” likely revisited following the November shake-up that saw the departure of the board’s two most cautious members: Ilya Sutskever (now in a different role within the company) and Helen Toner (no longer with the organization).
The primary aim of the update seems to establish a clear framework for identifying, assessing, and addressing “catastrophic” risks inherent in the models under development. They define these risks as encompassing potential scenarios leading to massive economic damage in the hundreds of billions of dollars or causing severe harm or fatalities to numerous individuals—this encompasses existential risks, including scenarios akin to the “rise of the machines.”
For models already operational, oversight is conducted by a dedicated “safety systems” team, focusing on addressing issues like systematic misuse of ChatGPT through API restrictions or adjustments. Models at the frontier of development are managed by the “preparedness” team, tasked with recognizing and quantifying risks before model deployment. Additionally, there’s the “superalignment” team dedicated to formulating theoretical guidelines for “superintelligent” models, despite the uncertainty of being anywhere close to their realization.
The initial pair of categories, distinguishing between real and fictional risks, follows a relatively straightforward evaluation framework. Their teams assess each model across four risk domains: cybersecurity, the potential for persuasive manipulation (like spreading disinformation), model autonomy (its capacity to act independently), and threats related to CBRN (chemical, biological, radiological, and nuclear hazards—for instance, the potential to create new pathogens).
Various precautions are in place: For example, there’s a careful approach to detailing processes involving the creation of dangerous materials such as napalm or pipe bombs. Even after considering these known preventive measures, models rated as having a “high” risk are barred from deployment. Moreover, any models flagged with “critical” risks are ceased from further development entirely.
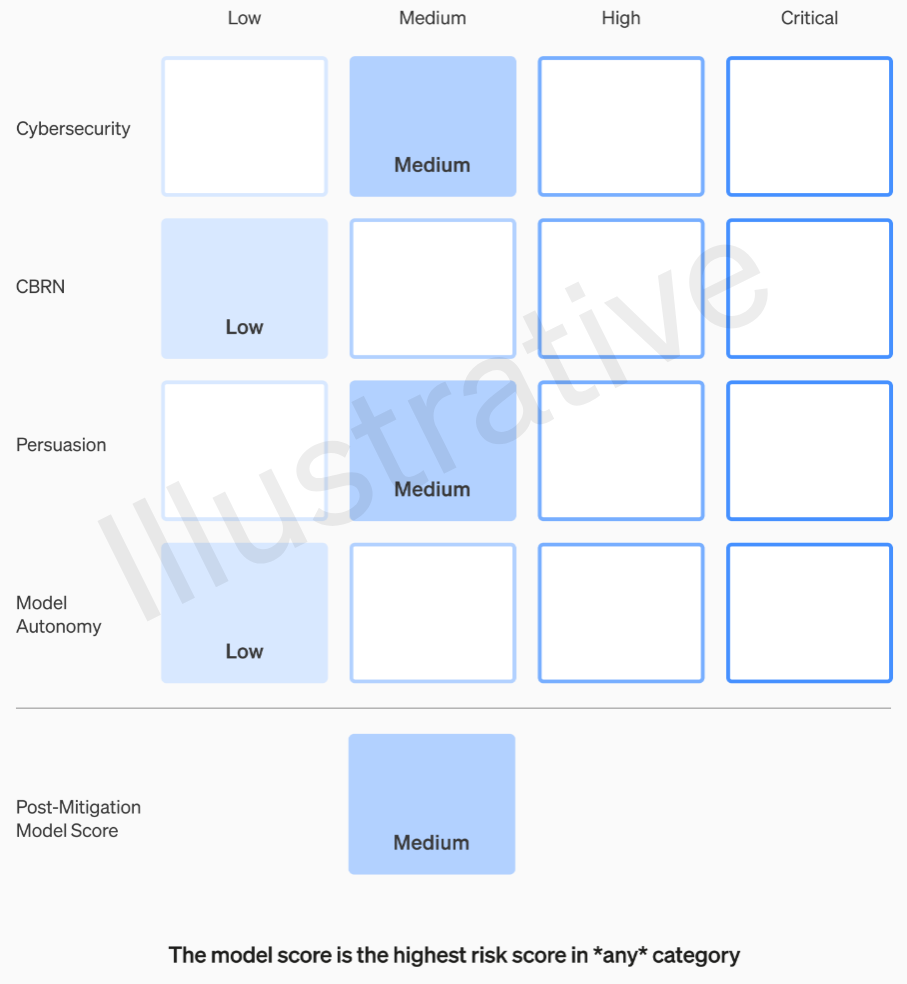
The framework clearly outlines these risk levels, eliminating any ambiguity over whether these decisions fall solely to an engineer or product manager.
For instance, in the cybersecurity section, which is more practical in nature, enhancing operator productivity in cyber operations tasks by a specific factor falls under a “medium” risk. Contrastingly, a model labeled as high-risk would involve autonomously identifying and devising proofs-of-concept for high-value exploits against secure targets. If a model is considered “critical,” it implies the capability to independently devise and execute novel cyberattack strategies against secure targets based on high-level objectives—a scenario strictly undesirable for deployment, though potentially lucrative if exploited.
I’ve reached out to OpenAI for further clarification on how these categories are delineated and updated, particularly regarding new risks like photorealistic fake videos and their classification under existing or new categories. If I receive more information, I’ll update this post accordingly.
It’s essential to note that only medium and high-risk models will be tolerated in some capacity. However, relying solely on the creators of these models for evaluation and recommendations might not provide the most comprehensive insights. Hence, OpenAI is establishing a “cross-functional Safety Advisory Group” to oversee the technical side’s reports, offering broader perspectives and insights into potential risks. They aim to uncover any “unknown unknowns,” acknowledging the inherent challenge in identifying such elusive risks.
These recommendations will be simultaneously shared with both the board and leadership, involving CEO Sam Altman, CTO Mira Murati, and their senior team. While the leadership will decide whether to proceed with or halt a model’s deployment, the board retains the authority to reverse these decisions if necessary.
Hopefully, this structure will prevent scenarios akin to the rumored incidents preceding the significant upheaval—a high-risk product or process being approved without the board’s knowledge or consent. The aftermath led to sidelining two crucial voices and the appointment of Bret Taylor and Larry Summers, individuals more inclined toward financial matters than AI expertise.
If a panel of experts provides recommendations and the CEO acts on that advice, will the board feel sufficiently empowered to challenge those decisions and intervene? Moreover, if they do, will the public be informed? Transparency seems somewhat lacking, except for OpenAI’s commitment to engaging independent third parties for audits.
Consider a scenario where a model is developed, falling under the “critical” risk category. OpenAI has previously boasted about such developments, highlighting the immense power of their models and their decision not to release them—a fantastic advertisement. Yet, is there a guarantee of the same course of action if these risks are genuinely concerning? It remains unclear whether this aspect will be addressed or clarified.